Frequently Asked Questions¶
Aggregate level changes when browsing from tables to charts¶
The aggregate level for tables is chosen to display a synthetic view on data, while the charts choose the aggregate level in order to have enough points to plot. Therefore, the aggregate level changing from one page to another is not an error.
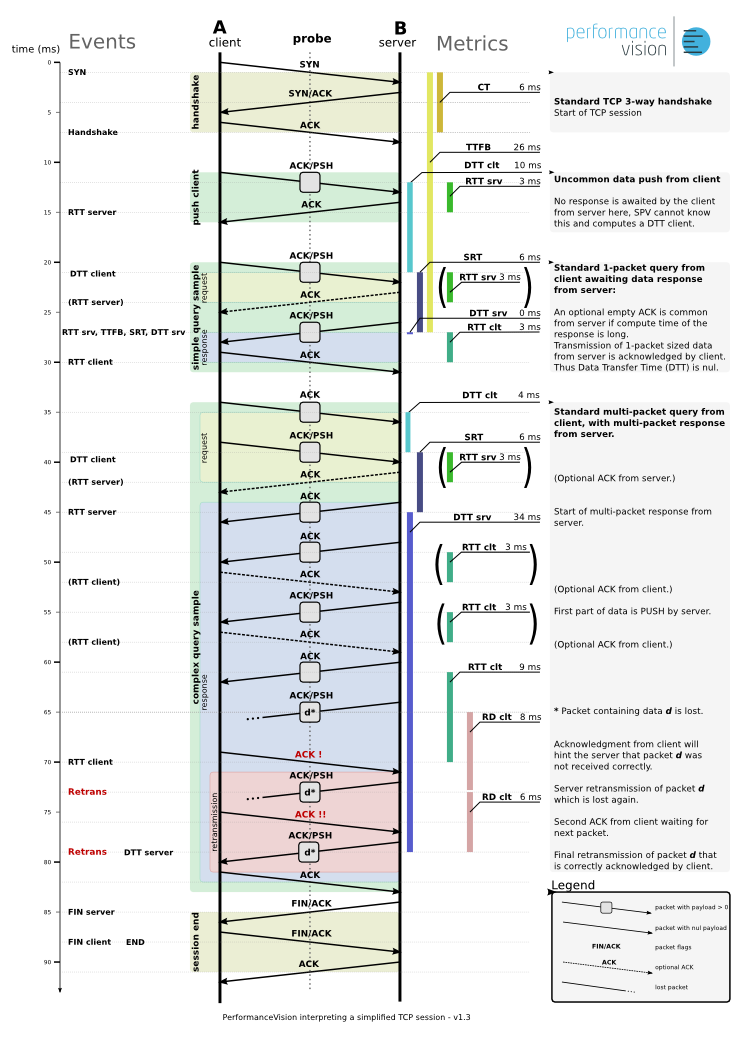
How can SRT be greater than DTT?¶
Every DTT is preceded by an SRT but both are not computed
simultaneously:
DTTsare not stored until the data transfer is complete;SRTsare stored as soon as the first packet of the response is seen.
Thus, it is common to have more SRTs than DTTs when browsing
recent data.
How can HTTP Page Load Time be lower than Hit Response Time?¶
The Page Load Time is the elapsed time between the first and
the last hit of the page; thus, logically, it should be greater
than the average Hit Response Time. Still, the page load time can
sometimes be lower than the average hit response time.
The reason is that some hits aren’t accounted for in the page load time computation. It is, in fact, becoming more and more common to use AJAX calls to load portions of the page, and SkyLIGHT PVX uses some heuristics to determine when the page has finished loading. This makes it so that some AJAX calls issued long after the page has loaded aren’t accounted for in the page load time computation. Yet they are hits of the page and their load times impact on the average hit response time.
Typically, when there are long AJAX calls after the page is loaded, the average hit response time may be greater that the page load time.
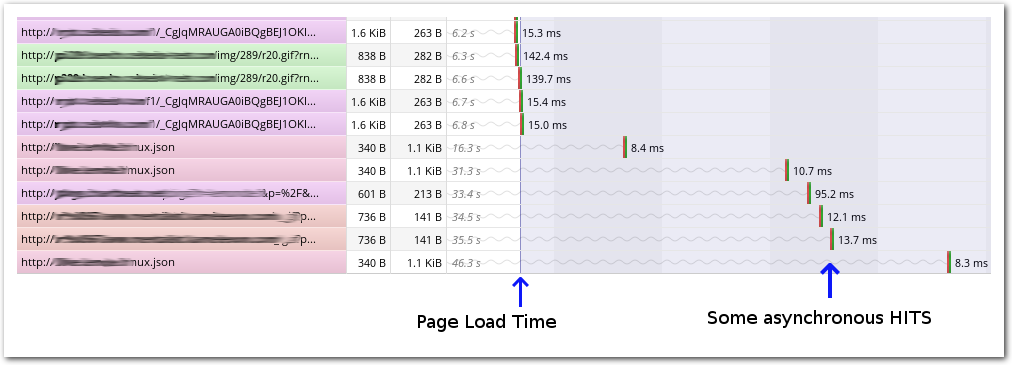
Asynchronous HITS after Page Load Time.
How can there be 0 packets and no traffic at all on a conversation?¶
This is common when the observation period encompass the end of a timeouted conversation. No packets have been sent during the observation period and the elapsed time since the last packet has reached the timeout limit.
Why are some DNS request names missing?¶
Although the DNS protocol states that the question section must be present in the requests, not all DNS messages are name resolution requests. Some DNS servers may use message types unknown to the traffic analyzer and do not embed anything meaningful in the question section of the message. The NBNS server statistic report is such a message that makes no use of the question section.
Note that you can search for empty DNS names using the regular
expression ~^$ in the name search box.
Some TCP conversations are reported twice, what’s wrong?¶
First, make sure that the deduplication process is not configured too tightly. If the faulty TCP conversations keep being reported twice, then maybe the duplicated packets are altered in some way that makes them too different from the originals. For instance, some firewalls randomize the ISN of TCP connections (for security reasons). So if you mirror some traffic before and after passing through such a firewall, this traffic will be reported twice since their sequence numbers will be different.
PCAP files generated by tcpdump are (mostly) empty¶
By far, the most probable reason for this is that you are trying to
use a filter on VLAN tagged packets. This won’t work since Tcpdump
filters look for fixed locations in the packet and the VLAN tag
offsets the actual bytes that are being matched. Fortunately, there is
a workaround: by adding the filter vlan, all following filters
will be offset by the VLAN tag size. For instance, if you want to
filter ip proto \tcp on an interface receiving only VLAN tagged
packets, then you must use the following filter instead:
vlan and (ip proto \tcp)
If the network interface receives both tagged and non-tagged packets, then this somewhat cumbersome filter must be used:
(ip proto \tcp) or (vlan and (ip proto \tcp))
How to do complex searches on domain names¶
On search boxes about domain names (Web and DNS reports), you can use
a regular expression by prefixing the entry with a tilde character
(~). For example, you can use this to filter all but some
names. Here is a valid input to filter all but Google’s and
Amazon’s:
~^(?!(.*\.)?google\.[fr|com]$)(?!.*amazon(\..{2,3}){1,2}$)
How come my VM keeps losing sync?¶
Even if you configure NTP on a virtual appliance, ESX “helper” programs will try to set the date and time of the VM from the ESX guest. This process will run concurrently with NTP date synchronisation with undefined results. If you have a VM that’s regularly out of sync, make sure your ESX itself has the correct time.